Use AI for Slow-Solve-Fast-Check tasks
In computer science there's a famous distinction between solving a task and verifying the solution. (You may know this in the context of P versus NP).
Think about a jigsaw puzzle: it can take hours and hours to put the pieces together, but once it's solved you can tell almost-instantly whether or not the solution is correct.
A simple model I have of current LLMs is that they're most useful for tasks that are slow to solve (for humans) but fast for us to verify.
You can imagine a simple 2x2 with "solving speed" along one axis and "checking speed" along another.
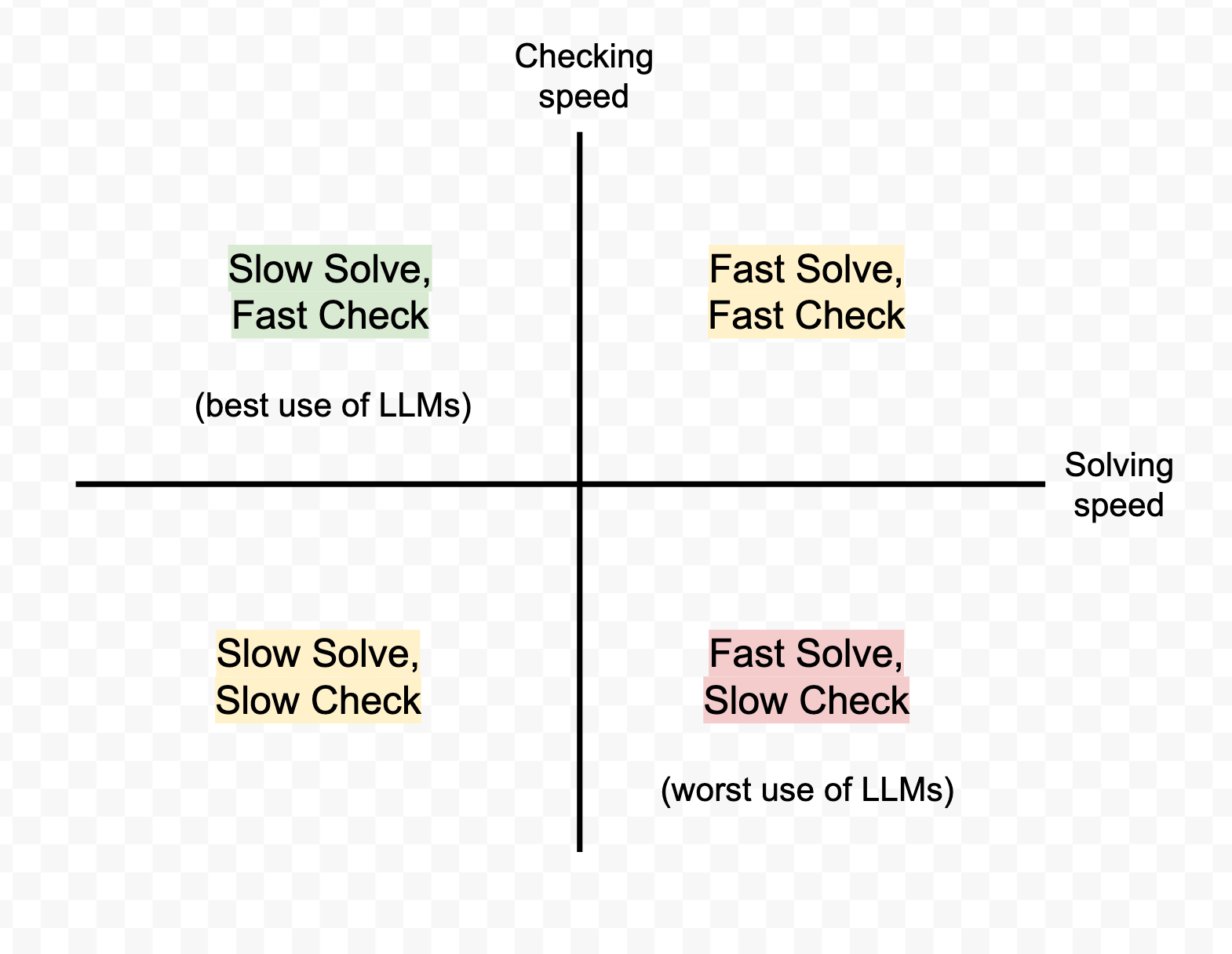
We can start placing tasks on this grid, such as:
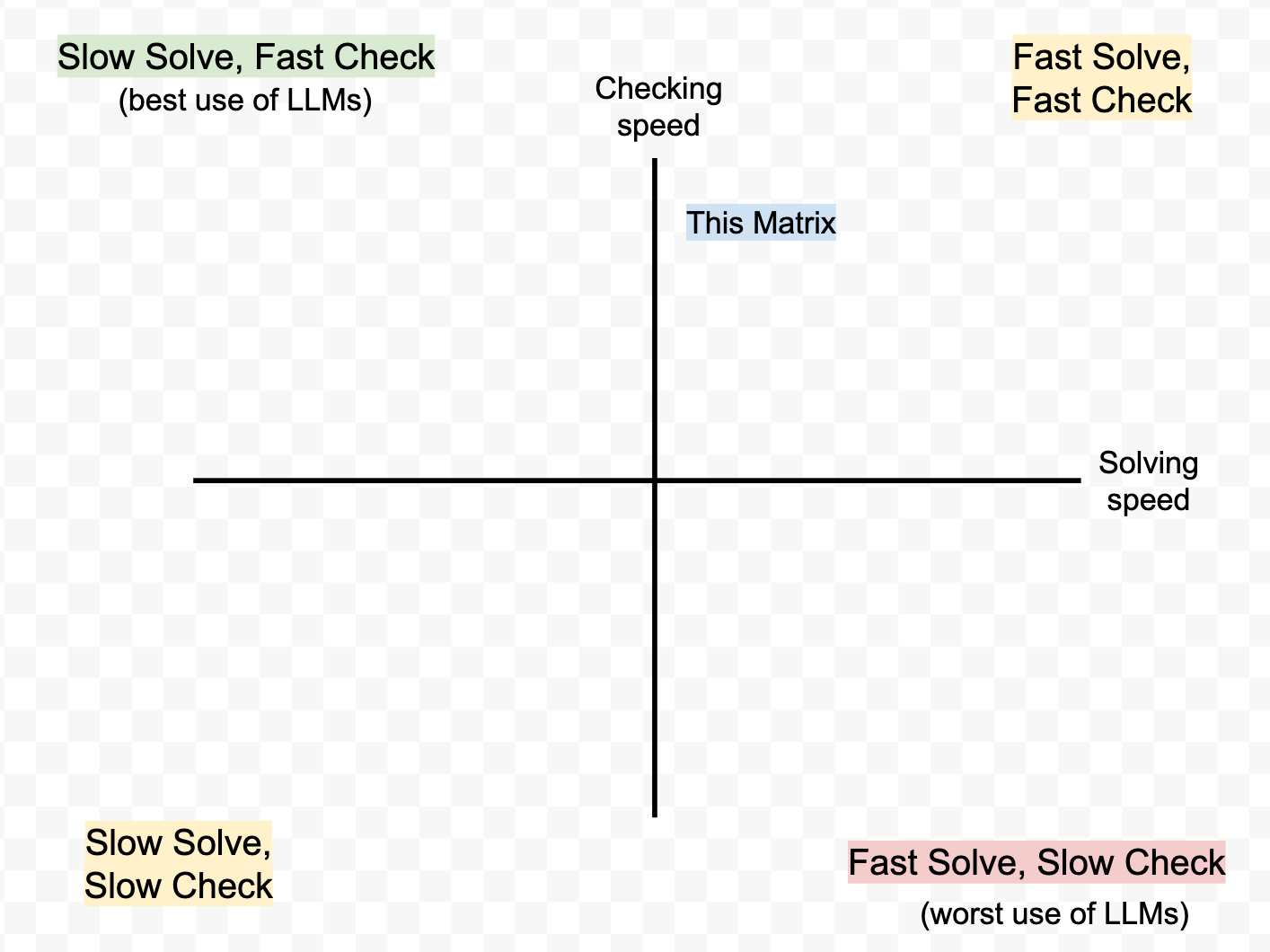
I first tried to get the LLM to help me with generating this 2x2, but the thing it made was wrong. I could immediately tell it was wrong (fast check), and I could have spent time prompting the LLM to get it right. But I knew I could also just make the thing in GoogleDraw in under a minute (fast solve), so I did that instead.
By contrast, the jigsaw puzzle analogy that I started this piece with came out of an LLM; I asked it "what's an example of an everyday task that is slow to solve but quick to verify?" Coming up with a good analogy takes time and effort, but deciding whether a proposed analogy is good or not can be near-instant.
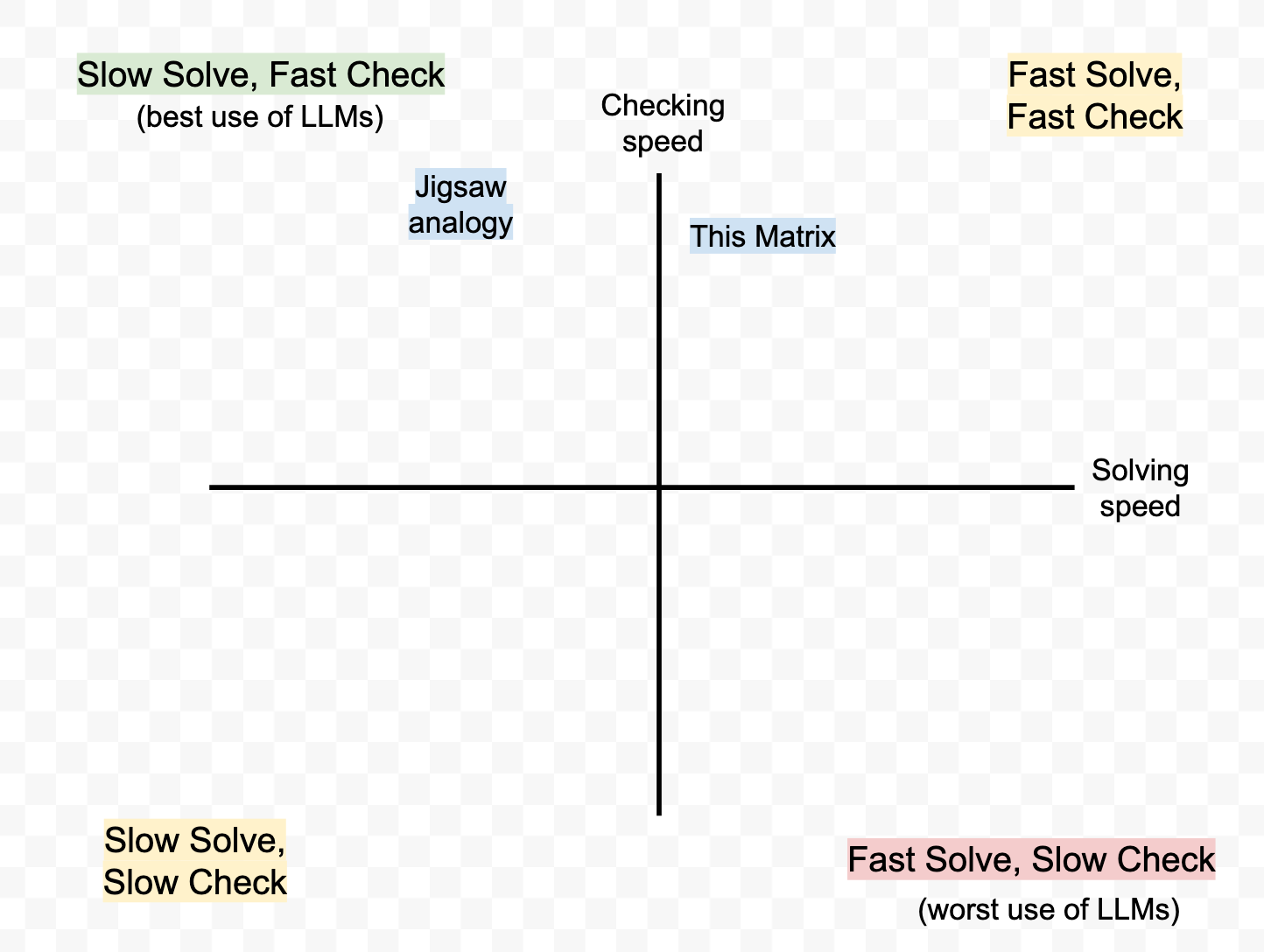
I think this is why LLMs are more generally great as "brainstorming partners" – it's slow for humans to come up with ideas, but fast for us to verify their quality.
Coding with LLMs is super fun, because the LLM can generate code 1000x faster than I can, but I can check whether it works pretty immediately (for small bits of code, at least – perhaps this changes with bigger project sizes).
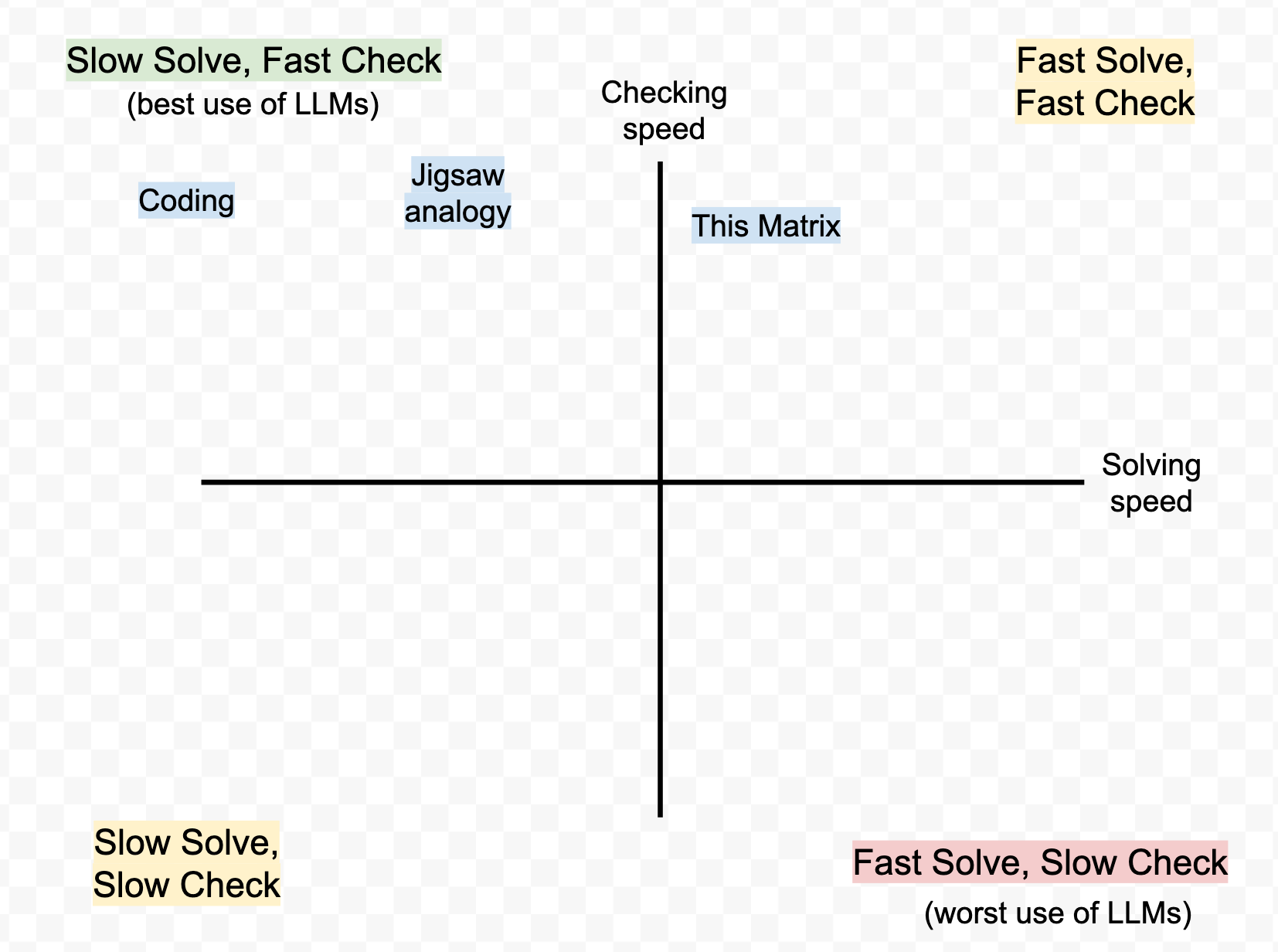
Research is kinda split in two, between domains where you know things and where you don't know things:
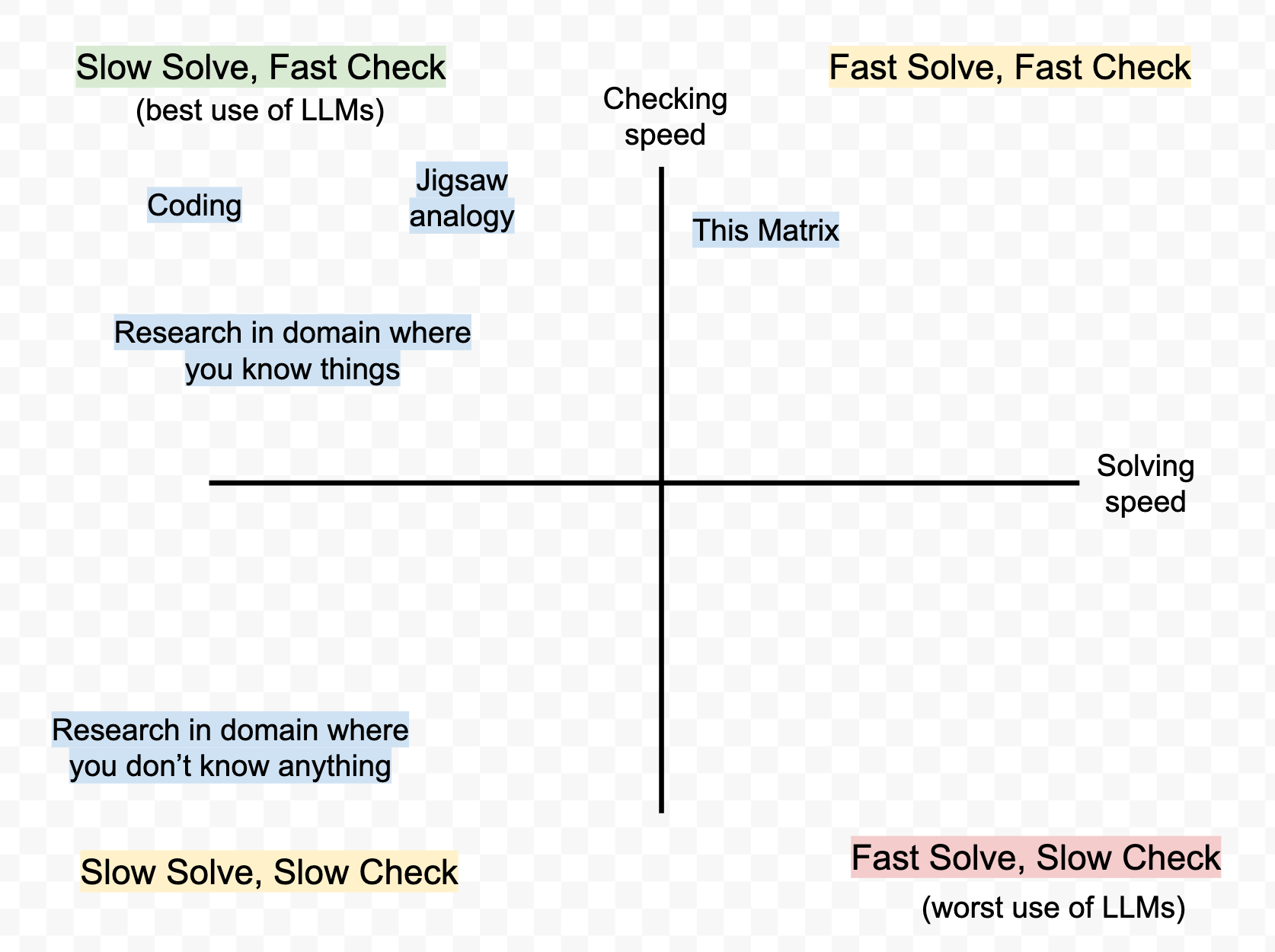
Basically, in domains where I don't know anything it would take me a while to find the answers I want, but also I can't really tell if what the LLM gives me has obvious errors in it, so I'm not really convinced that the net outcome is better than 0.
By contrast, in a domain where you know things, maybe it's helpful to have the LLMs research a question for you because you can instantly check whether the result is accurate? (For me this is entirely hypothetical, if you know things about anything feel free to reply in the comments).
This also highlights the differing opinions about LLMs as Essay Writers between two types of purposes:
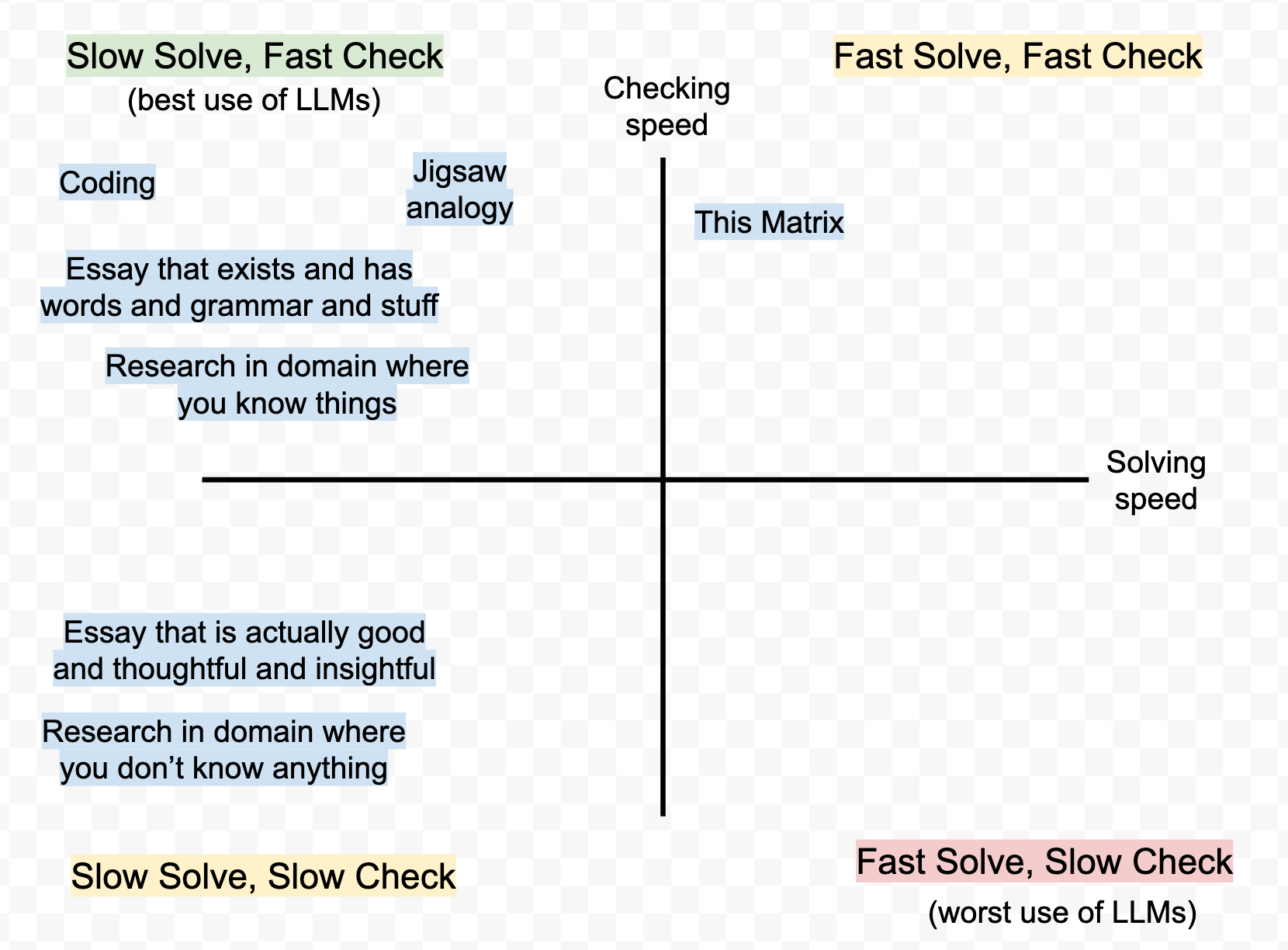
For many people, the goal of essay writing is "get words on the page that form sentences and look grammatical," and historically this takes humans a reasonable amount of time to do themselves, but they can tell in 10 seconds that an LLM has done it correctly.
For other people, the goal of writing essays is "write something good and thoughtful and insightful." This is slow to do, but also slow to check: you actually have to think about the things, and check if they're true, and this takes time. So using an LLM is no longer an obvious win.
Anyway. I think human brains are kind of easily hacked by neat models and 2x2 matrices, which often feel truthy whether or not they're true. So let me end by mentioning two other axes that can be useful when evaluating how good an LLM is for a task:
- how good are LLMs at this task? Note that this is weirdly missing from my model above, which means it's probably getting snuck in implicitly somewhere.
- do you need an output that's precise, or just approximate? Another model of LLM-use is just that they're good at tasks where you only need an approximate answer (e.g. there are many different Ghibli variants on your photo that would all look lovely) and bad when you need a precise one (e.g. when creating a 2x2, I need specific text to appear at specific places on the graph).
I think ideally we would either find 1) some interesting test cases that would generate different predictions between different models, or 2) a bigger model that incorporates one more axis. But alas, my brain is done – if you have energy to continue this model please do.